
Vom Universum ins Unternehmen: Wie die Radioastronomie den Unternehmen nutzen kann © SKAO
Von Big Bang zu Big Data
Riesige Datenmengen, die stetig weiterwachsen – eine Herausforderung, der sich aktuell und zukünftig jedes Unternehmen stellen muss. Sie fallen – bewusst gesteuert oder auch als bisher nicht beachtetes Beiprodukt – in unterschiedlichen Bereichen an, beispielsweise auf dem Shopfloor, in der Qualitätssicherung, im Einkauf oder auch bei allen Finanzthemen. Doch was zunächst nach einer kaum zu bewältigenden Datenflut klingt, kann durchaus als Chance für Unternehmen gesehen werden. Die vorhandenen Daten können genutzt werden, um damit das eigene Wertschöpfungspotenzial zu steigern, Kostenstrukturen zu optimieren oder gleich ganz neue Umsatzströme anhand von datenbasierten Geschäftsmodellen zu generieren. Um zu verstehen, wie riesige Datenmengen zu brauchbaren Informationen werden, kann ein Blick in die Radioastronomie helfen, wo entsprechende Technologien und das benötigte Know-how bereits vorhanden sind.
Mit dem gesamten Internet vergleichbare Datenmengen händeln
Radioastronomen und Radioastronominnen entwickeln fortlaufend neue Methoden und Algorithmen, um aus riesigen Mengen an Beobachtungsdaten die wirklich relevanten Daten zu filtern. Nur so können ungewöhnliche Galaxien oder neue Arten von Sternen und Planeten, aber auch für die Erde gefährliche Asteroiden entdeckt werden. Der Bau immer größerer und leistungsstärkerer Radioteleskope führt auch zu einem enormen Wachstum der ohnehin schon gigantischen Datenberge. So generiert beispielsweise MeerKAT in Südafrika mehrere Petabytes (1015) Daten pro Beobachtungstag. Das Square Kilometre Array Observatory (SKAO), das derzeit in Südafrika und Australien entsteht, wird diese Datenmenge um ein Vielfaches übersteigen.
Best Practice: Visuelle End-of-Line-Prüfung
Die Handhabung und Analyse dieser enormen Datenmengen ist also eine tägliche Herausforderung für Astronominnen und Astronomen. Man könnte fast schon sagen, sie sind eigentlich Datenwissenschaftler mit der Fachrichtung Astrophysik. Unter dieser Perspektive ist es dann auch wenig verwunderlich, dass die hierbei erworbenen Kenntnisse an vielen Stellen in der Industrie zum Einsatz kommen können, werden zur Produktionsoptimierung oder Qualitätskontrolle doch überall Data Scientists gesucht.
Unmittelbar greifbar wird dies, betrachtet man konkrete Best-Practice-Beispiele, wie etwa das Auffinden von Outlier-Objekten in großen Sätzen von Bildern. In der Astrophysik werden so etwa sonderbare Objekte in großen Himmelsdurchmusterungen aufgespürt, die potenziell den nächsten Nobelpreis einbringen können. In der industriellen Produktion jedoch sind mit denselben algorithmischen Ansätzen kamerabasierte Prüfverfahren zu automatisieren, denn bei der Produktion etwa von Elektronikkomponenten fallen ähnlich viele Einzelbilder an, die auf Ausreißer, also Schlecht-Teile, kontrolliert werden müssen. Doch was geschieht, wenn keine Bilder von defekten Teilen zur Verfügung stehen, um einen Bilderkennungsalgorithmus anzulernen? Muss erst so lange gewartet werden, bis es trotz ausgefeilter Montage-Optimierung dann doch mal zu einem Fehler kommt? Oder müssen sogar potenziell teure Teile vorsätzlich zerstört werden, um Defekte zu simulieren?
Die kurze Antwort dazu lautet: Jetzt nicht mehr! »In den letzten Jahren haben wir immer wieder erkannt, dass die Notwendigkeit zum Einlernen von Schlecht-Bildern den Einsatz von kognitiven Assistenzsystemen massiv behindert. Zur weiteren Verbreitung der Technologie im konkreten Shopfloor-Einsatz braucht es daher eine komfortable Lösung, die es ermöglicht, ausschließlich mit Bildern des regulär laufenden Prozesses zu trainieren und trotzdem Abweichungen von der Norm erkennen zu können, ganz so wie es auch ein Mensch tun würde«, beschreibt Dr. Peter-Christian Zinn das Industrie-Problem. Als studierter Astrophysiker, der mittlerweile mehrere Unternehmen mit dem Schwerpunkt auf datengetriebenen Geschäftsmodellen gegründet hat, kommt Zinn dieses Problem bekannt vor. Mit seinem Industrial Analytics Lab, das auf die Implementierung von KI-gestützten Automationslösungen gerade im Mittelstand spezialisiert ist, nutzt er daher regelmäßig Know-how über entsprechende Algorithmik zur Bilddatenverarbeitung aus der Astronomie, um damit Probleme in der Wirtschaft zu lösen.
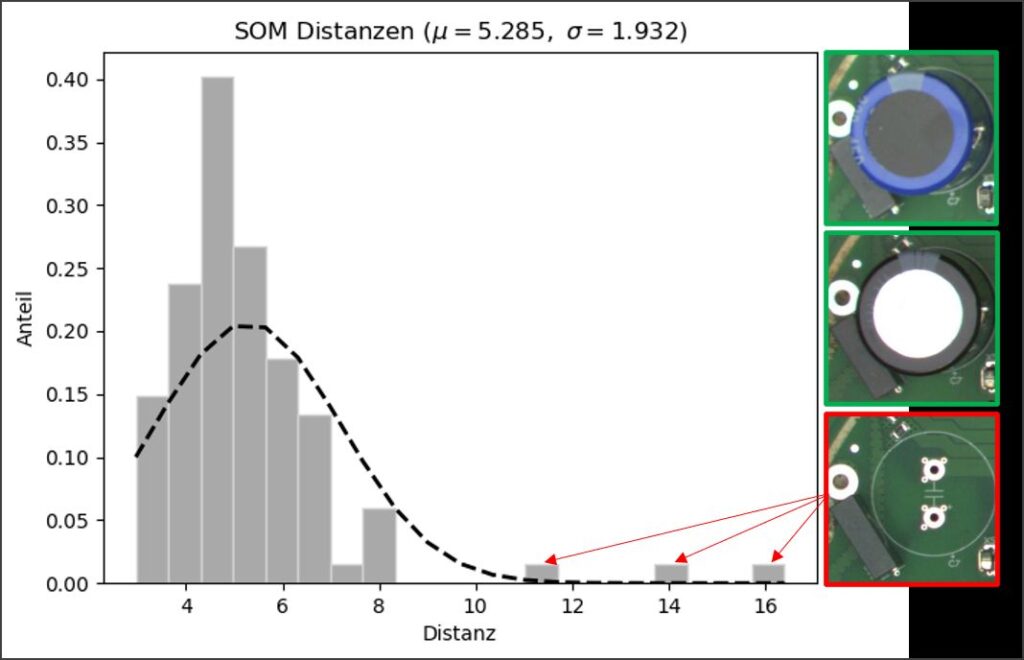
Möglich wird dies durch den Einsatz von Self-Organizing-Maps (SOMs) oder zu Deutsch: selbstorganisierende Karten. Sie stellen einen Sonderfall in der großen Familie der Neuronalen Netze – der mittlerweile bekanntesten Gruppe von Verfahren des Maschinellen Lernens in der Bilddatenverarbeitung – dar. Sie gehören insbesondere zu den sogenannten Unsupervised-Learning-Methoden. Das bedeutet, dass eine Klassifikation von Bilddaten ohne a priori Wissen ausschließlich basierend auf algorithmisch identifizierter Ähnlichkeit der Bilder durchgeführt wird. Dies ermöglicht Klassifikationsaufgaben ohne vorherige Kenntnis der Anzahl und Art der zu bildenden Klassen. Befinden sich in einem Satz Bilddaten etwa Fotografien von Hunden, Katzen und Mäusen, so wird die SOM eine dreiteilige Gliederung ganz von selbst herausbilden. Kommt dann z. B. die Fotografie eines Vogels hinzu, wird diese in keine der drei Teile der Karte einsortiert werden können und entsprechend an den Rand der Karte rücken und so als Ausreißer deutlich hervortreten. Da der Name bei SOMs auch Programm ist (»Karte« ist hier wörtlich zu nehmen), kann sogar ein Bestimmtheitsmaß für die so erfolgte Klassifikation ermittelt werden, da der Abstand in der Karte ein direktes Maß für die Ähnlichkeit darstellt. Je weiter weg, desto unähnlicher.
Durch dieses intuitive Ähnlichkeitsmaß wird gleichzeitig erreicht, dass der Algorithmus für seine menschlichen »Kolleg*innen« nachvollziehbar bleibt und sie so Vertrauen in die Qualitätsentscheidungen der Maschine fassen. Schließlich sollen entsprechende, KI-basierte Assistenzsysteme stets als hilfreiches Werkzeug für den Menschen fungieren, niemals jedoch die Letztentscheidung vorwegnehmen oder gar als »Konkurrenz« angesehen werden.
Big Bang to Big Data – Profile bilden und Strukturen schaffen
Um das Verständnis und die Verarbeitung großer Datenmengen synergetisch zu verbessern sowie auf die wachsende Datenflut methodisch und infrastrukturell vorzubereiten, fördert das Ministerium für Kultur und Wissenschaft des Landes Nordrhein-Westfalen den Cluster »Big Bang to Big Data« (B3D). B3D vereint radioastronomische Forschung mit datenwissenschaftlicher Expertise. Radioastronomische Datenströme werden der Wissenschaft und Industrie zugänglich gemacht, um neue Algorithmen zu entwickeln und zu testen.
Auf Basis der B3D-Ergebnisse soll in fünf Jahren ein »Big Data Campus« in NRW entstehen, bei dem automatisierte Verfahren der Datenverarbeitung und des Qualitätsmanagements mit Big-Data- und KI-Methoden weiterentwickelt werden und Unternehmen die Möglichkeit haben, industrielle Anwendungen zu testen. Hiermit einher geht das Ziel, für den wissenschaftlichen Nachwuchs in diesem interdisziplinären Kontext neue Qualifizierungsprogramme zu etablieren.
Über die Autoren

Transfermanagerin am Max-Planck-Institut für Radioastronomie in Bonn

Managing Partner beim Industrial Analytics Lab und Data Science Fellow beim Bochumer Institut für Technologie